Với chức vô địch Premier League trong tầm tay, Manchester City tới Fulham cho cuộc đụng độ quan trọng trong nước sắp tới vào cuối tuần. Trận đấu sẽ bắt đầu ngày thi đấu thứ 37 của giải đấu hàng đầu nước Anh vào ngày 11 tháng 5 tại Craven Cottage. Hãy xem bài viết soi kèo Fulham vs Man City bên dưới từ nhà cái Five88 để có thể đặt kèo chính xác nhất.

Thông tin chung về 2 đội 5 trận đấu gần đây
Đội bóng Fulham: Fulham có thành tích trung bình trong mùa giải, hiện đang giữ vị trí thứ 13 trên bảng xếp hạng với 44 điểm sau 36 trận, trong khi chỉ thắng 12 trận trong suốt thời gian đó. Họ sẽ bước vào trận sân nhà gặp Man City sau trận hòa không bàn thắng trước Brentford. Đó là trận hòa thứ bên bên cạnh 1 chiến thắng, 2 trận thua trong 5 trận gần đây.
Đội bóng Man City: Manchester City, nhà đương kim vô địch Premier League, sẽ bước vào trận đấu với Fulham sau chiến thắng 5-1 trước Wolves cuối tuần trước. Qua đó, đánh dấu chuỗi 5 trận bất bại gần đây. Họ hiện kém đội đầu bảng Arsenal một điểm nhưng còn một trận trong tay. Một chiến thắng nữa trước Fulham vào cuối tuần này sẽ đưa họ lên đầu bảng xếp hạng.

Xem thêm:
- Soi kèo Frosinone vs Inter Milan 01h45 11/05/2024 Serie A
- Soi kèo Augsburg vs Stuttgart 01h30 11/05/2024 Bundesliga
Lịch sử đối đầu giữa 2 đội trong quá khứ
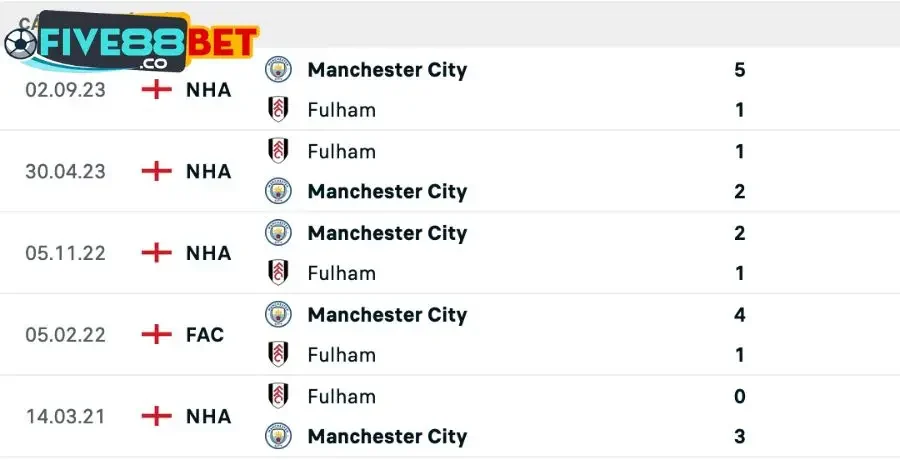
Hai câu lạc bộ Anh đã đối đầu với nhau 35 lần trên mọi đấu trường cho đến nay. Manchester City đã giành chiến thắng trong 22 trận đấu này, trong khi Fulham chỉ thắng 4 lần, 4 trận còn lại đều kết thúc với tỷ số hòa. Trong trận đấu gần đây nhất, Man City đã giành chiến thắng 5-1 trước Cottagers. Với sự vượt trội về mọi mặt cùng thành tích đối đầu thì không có lý do nào khác để soi kèo nhà cái nghiêng về chiến thắng cho đội khách.
Dự đoán tỉ số
Fulham 1-3 Man City
Soi kèo tài xỉu
Fulham của Marco Silva đã nhận được phần thưởng cho những nỗ lực ghi bàn của họ tổng cộng 5 lần trong 6 trận ra quân trước đó. Số bàn thua tương ứng mà họ phải nhận trong thời gian đó là 8. Do đó, cơ hội ghi bàn vào lưới Man City là có nhưng đội chủ nhà phải đón nhận thiệt hại nhiều hơn từ hàng công ấn tượng của đội khách với 13 bàn sau 5 trận mới nhất.
Chọn tài 1.5 (H1)
Chọn tài 3.5 (Full Time)
Soi kèo châu Á (kèo chấp)
Fulham được thi đấu trên sân nhà nhưng họ vẫn bị coi là đội cửa dưới bởi khoảng cách sức mạnh so với Man City khá lớn. Dù vậy, tỷ lệ chấp bàn thắng sẽ không quá cao ở đây và cơ hội để đội khách giúp người chơi thắng kèo Châu Á khá rõ ràng, đặc biệt là khi đội bóng của Pep Guardiola đã bất bại trên sân khách trong 10 trận gần nhất.
Chọn Man City 0.76 (H1)
Chọn Man City 0.94 (Full Time)
Các kèo đặc biệt
Với tỷ lệ thắng trung bình luôn trên 70% trên cả sân nhà lẫn sân khách của Man City cùng thành tích toàn thắng trước Fulham khi 2 đội gặp nhau trong 5 lần gần nhất thì cơ hội thắng kèo Châu Âu theo các chuyên gia từ soi kèo Ngoại Hạng Anh khi đặt cửa đội khách rất cao.
Đội hình dự kiến
Fulham: B. Leno; Castagne, I. Diop, Bassey, A. Robinson, Palhinha, Lukic, Willian, Pereira, Traore, Raul Jimenez.
Man City: Ederson; Walker, Dias, Stones, Gvardiol; Rodri, Kovacic; Foden, De Bruyne, Grealish, Haaland.
- Kèo Cầu Thủ Nhận Thẻ Phạt: Dự Đoán Chuẩn Xác Nhất Tại FIVE88 - Tháng tư 18, 2025
- Kèo Số Thẻ Phạt Chính Xác: Bí Quyết Ẵm Thưởng Lớn Tại Five88 - Tháng tư 18, 2025
- Kèo Tỷ Số Hiệp 1: FIVE88 Bật Mí Bí Kíp Độc Quyền, Thắng Lớn - Tháng tư 18, 2025







